데이터베이스를 설계하여 생성하는 업무를 맡았다고 가정해봅시다. 좋은 데이터베이스를 설계하는 것은 매우 중요한 작업입니다. 부주의한 데이터베이스 설계는 제어할 수 없는 데이터 중복을 야기하여 여러 가지 갱신 이상(update anomaly)을 유발합니다. 그렇다면 어떻게 좋은 데이터베이스를 설계해야 할까요? 데이터베이스에 어떤 릴레이션을 생성해야 할까요? 각 릴레이션에 어떤 애트리뷰트를 만들어야 할까요?
01. 릴레이션의 정규화
좋은 관계 데이터베이스 스키마를 설계하는 목적은 ➀ 정보의 중복과 갱신 이상이 생기지 않도록 하면서, ➁ 정보의 손실을 막고 실세계를 훌륭하게 나타내며 ➂ 애트리뷰트들 간의 관계가 잘 표현되는 것을 보장하며, ➃ 어떤 무결성 제약조건의 시행을 간단하게 하여 ➄ 효율성 측면을 고려하는 것입니다.
실세계를 훌륭하게 나타낸 설계는 직관적으로 이해하기 쉬우며, 미래의 성장에 잘 대비할 수 있는 설계를 의미합니다. 먼저 갱신 이상이 발생하지 않도록 노력하고, 그다음에 효율성을 고려합니다.
ER 데이터 모델을 기반으로 고수준의 스키마를 생성하고, 이 설계를 릴레이션들의 집합으로 사상한 후에 함수적 종속성을 기반으로 릴레이션들을 재구성합니다. 릴레이션을 재구성할 때 릴레이션을 어떻게 분해하는가에 따라 좋은 분해와 나쁜 분해로 구분할 수 있습니다. 나쁜 분해는 정보의 손실을 초래합니다. 좋은 분해에서는 분해된 릴레이션들을 조인하면 원래의 릴레이션을 만들어낼 수 있습니다.
관계 데이터 모델을 제안한 E.F. Codd는 검색 및 갱신 문제를 유발하는 릴레이션의 구조적인 특징들을 밝혀냈습니다. 정보의 중복은 나쁜 릴레이션 스키마로부터 발생되는 많은 문제들의 원인이 됩니다. 아래의 문제들 중에서 수정 이상, 삽입 이상, 삭제 이상을 총칭하여 갱신 이상이라고 부릅니다.
| 정보의 중복 | 정보의 중복은 동일 정보를 두 곳 이상에 저장하는 것을 말합니다. |
| 수정 이상 (modification anomaly) |
반복된 데이터 중에서 일부만 수정하면 데이터의 불일치가 발생합니다. |
| 삽입 이상 (insertion anomaly) |
불필요한 정보를 함께 저장하지 않고는 어떤 정보를 저장하는 것이 불가능합니다. |
| 삭제 이상 (deletion anomaly) |
유용한 정보를 함께 삭제하지 않고는 어떤 정보를 삭제하는 것이 불가능합니다. |
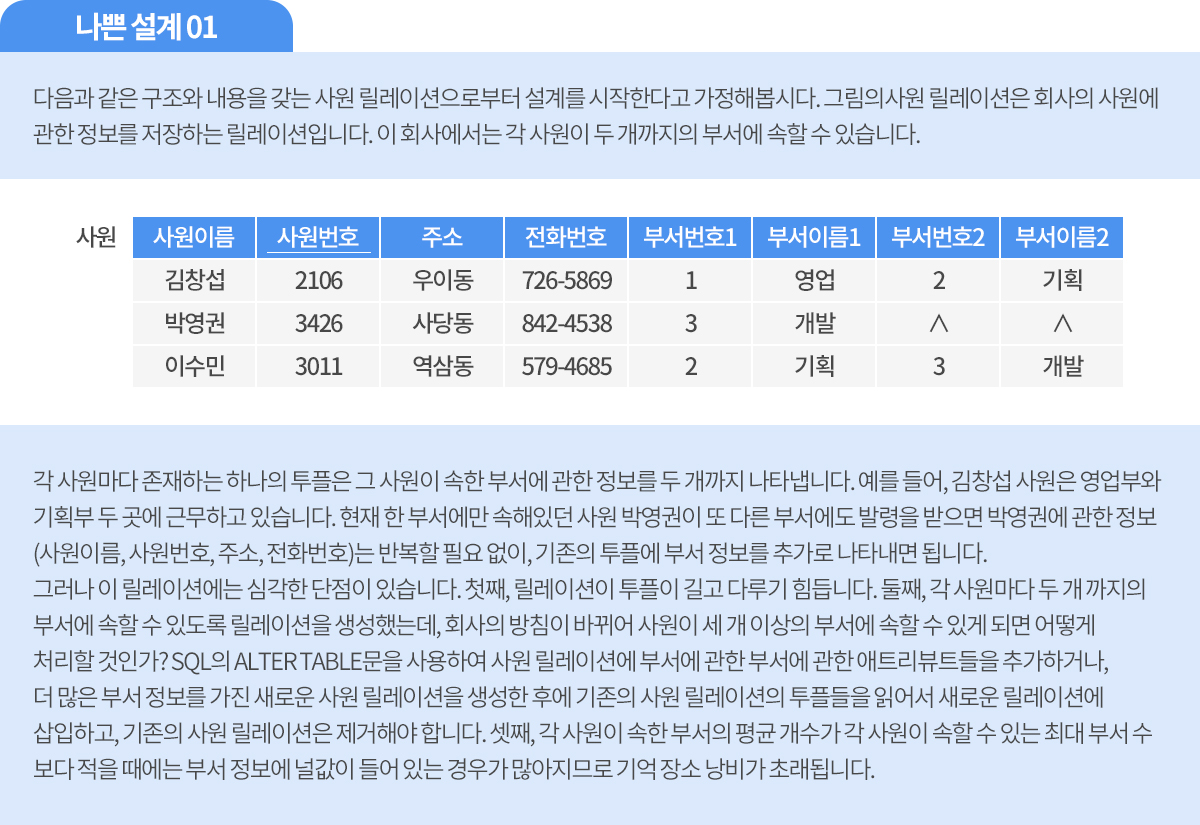

위의 두 가지 설계 예에서 나온 바와 같이 나쁘게 설계된 릴레이션 또는 정규화되지 않은 릴레이션들은 저장 공간을 낭비하고, 세 가지 갱신 이상을 유발하게 됩니다. 정규화는 주어진 릴레이션 스키마를 함수적 종속성과 기본 키를 기반으로 분석하여 원래의 릴레이션을 분해함으로써 중복과 세 가지 갱신 이상을 최소화하는 것입니다.
정규화가 진행되면 기존의 릴레이션은 분해됩니다. 릴레이션 분해는 하나의 릴레이션을 두 개 이상의 릴레이션으로 나누는 것입니다. 릴레이션의 분해는 필요한 경우에는 분해된 릴레이션들로부터 원래의 릴레이션을 다시 구할 수 있음을 보장해야 한다는 원칙을 기반으로 하므로 두 릴레이션으로 얻을 수 있는 정보는 원래의 릴레이션일 갖고 있던 정보와 정확하게 일치해야 합니다.
[ 사원 1 ]
| 사원이름 | 사원번호 | 주소 | 전화번호 | 부서번호 |
| 김창섭 | 2106 | 우이동 | 726-5869 | 1 |
| 김창섭 | 2106 | 우이동 | 726-6869 | 2 |
| 박영권 | 3426 | 사당동 | 842-4538 | 3 |
| 이수민 | 3011 | 역삼동 | 579-4685 | 2 |
| 이수민 | 3011 | 역삼동 | 579-4685 | 3 |
[ 부서 ]
| 부서 번호 | 부서 이름 |
| 1 | 영업 |
| 2 | 기획 |
| 3 | 개발 |
[사원 릴레이션을 사원 1 릴레이션과 부서 릴레이션으로 분해]
이와 같이 분해했을 때 어떻게 갱신 이상 문제가 완화되는지 알아봅시다. 사원 1 릴레이션에 각 사원이 속한 부서 개수만큼 투플이 존재하므로 여전히 사원 이름, 사원번호, 주소, 전화번호가 중복되므로 어떤 사원의 전화번호나 주소 등이 변경되면 이 사원에 관한 모든 투플에서 변경해야 합니다.
❶ 부서 이름의 수정
어떤 부서에 근무하는 사원이 여러 명 있더라도 사원 1 릴레이션에서는 부서 이름이 포함되어 있지 않으므로 수정 이상이 나타나지 않는다.
❷ 새로운 부서를 삽입
만일 어떤 신설 부서에 사원이 한 명도 배정되지 않았더라도, 부서 릴레이션의 기본 키가 부서 번호이므로 이 부서에 관한 정보를 부서 릴레이션에 삽입할 수 있습니다.
❸ 마지막 사원 투플을 삭제
만일 어느 부서에 속한 유일한 사원에 관한 투플을 삭제하더라도 이 부서에 관한 정보는 부서 릴레이션에 남아 있습니다.
▶︎ 관계 데이터베이스 설계의 비공식적인 지침
왜 어떤 릴레이션 스키마가 다른 릴레이션 스키마보다 좋을까요?
첫째, 각 릴레이션은 독자적으로 의미를 갖는 단위가 되어야 합니다.
여러 엔티티에 속하는 애트리뷰트들이 하나의 릴레이션 스키마에 포함되면 정보의 중복이 발생합니다. 정보가 반복이 되면 삽입 이상, 수정 이상, 삭제 이상이 발생하므로 정보의 반복을 최대한 피해야 합니다.
둘째, 널값은 정보의 해석에 어려움을 야기하므로 가능한 한 널값은 피해야 합니다.
널값일 가능성이 높은 애트리뷰트를 릴레이션에 포함시키지 않아야 합니다. 널값은 저장 공간이 늘어나며, sum이나 count와 같은 집단 함수를 적용하기 어렵고, 조인을 하기 어렵고 여러 가지 의미를 갖는 문제를 유발하기 때문입니다.
셋째, 가짜 투플이 생기는 조인은 피합니다.
기본 키 또는 외래 키로 사용되는 애트리뷰트들 간에 동등 조건으로 조인할 수 있도록 릴레이션들을 설계해야 합니다.
넷째, 스키마를 정제합니다.
여러 가지 갱신 이상을 피하기 위해서 개념적 설계 단계에서 고려한 것보다 더 완전하게 무결성 제약조건들을 고려함으로써 설계를 정제해야 합니다.
'💕IT 공부하기 > 데이터베이스' 카테고리의 다른 글
| 릴레이션 분해(decomposition)과 제1정규형 (1) | 2022.09.19 |
|---|---|
| 함수적 종속성에 대해 알고계신가요? (0) | 2022.09.16 |
| 물리적 데이터베이스 설계에 대하여(5) (0) | 2022.09.14 |
| 물리적 데이터베이스 설계에 대하여(4) (0) | 2022.09.13 |
| 물리적 데이터베이스 설계에 대하여(3) (0) | 2022.09.12 |